
This is a cultural analytics project which aims to propose the scope, materials and approaches for a Digital Humanities oriented research that includes and relies to some extent on the element of Python coding.
The project consists of proposal and python coding, followed by an essay which critically describes and assesses the act of coding and building things in the digital humanities.
Proposal
The Assassin (2015) is a wuxia film (a sub-genre of the martial arts film based on mythology and often associates with political conflicts) directed by Hou Hsiao-hsien. Once the film was released, there were polarised discussions about the story and mise-en-scene (such as colour, lighting, composition and so on) in China due to difficulty of interpretating and understanding. The same discussions happened on Rotten Tomatoes as the tomatometers (critics) give the film 80% of freshness, while there is 47% of audience has rated 3.5 stars or higher. My project aims to investigate what do western audience think of the story and mise-en-scene of this film, and how much do they understand and like the film. The project tries to state that western audience are able to interpret the film’s story and mise-en-scene very simply, as the generated WordCloud shows words like ‘beautiful’, ‘martial’, ‘Chinese’. The polarised discussions exist due to both positive and negative adjectives in 50 highest-frequency words chart. The average sentiment tends to be neutral, which means they do not show obvious preferences of this film. In conclusion, mise-en-scene is able to work effectively on a very basic level of interpretation for the western audience, but probably fails to evoke more responses on cultural dimension.
The project will mine the data which contains a total of 284 reviews on Rotten Tomatoes from both critics and audience to produce average analysis. The implementation will be divided into four steps. Firstly, I will use BeautifulSoup to create two loops to iteratively scrape all the content includes names, dates, reviews and scores from both audience and critics. Secondly, I will import Pandas and use DataFrame to visualise the scraped data in a chart. Thirdly, I will use WorldCloud to visualise some most frequency words. The aim is to offer a simple overview of the words that being mentioned the most in all the reviews. Fourthly, in order to process more accurate analysis of word frequency of reviews, the NLP will be applied to process by following a process order of segmentation, cleaning, normalisation and tokenisation. By using matplotlib, the 50 highest-frenquency words will be visualised to form a line chart in order to see counts of each word and the variation between all these words. Finally, the sentiment analysis will be applied to get polarity and subjectivity of each piece of review and the mean scores of all the reviews.
Scholars could be able to compare the analysis with others across different platforms, discovering and annotating implications of the data, digital platforms. On the other hand, research questions such as ‘in what ways mise-en-scene can help people from different culture backgrounds understand certain culture elements effectively’ could be formed. For the public, reviews could be used to decide whether they should watch the film or not. Economically, the data can be referenced by film production companies for marketing analysis and the data is able to applied on producing other films.
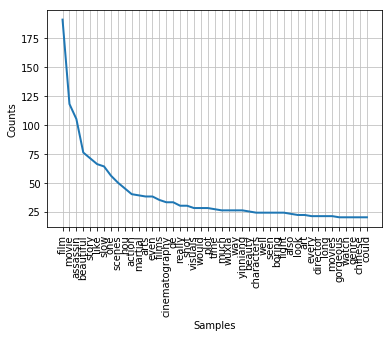
Word frenquency
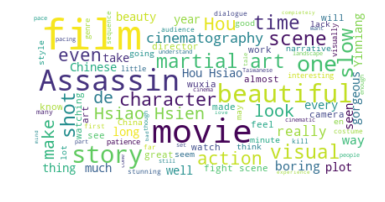
Word cloud
Code
Click here to check python coding.
Essay
What is the nature of the building of knowledge co-creation model through crowdsourcing of film reviews? In what ways do coding help or hinder to build the model?
Please check the essay on the individual post.